Sample dataset
This is what a dataset drop looks like. We deliver in native LeRobot v2.0 format with pre-computed normalization statistics—ready for VLA fine-tuning without any conversion.
LeRobot v2.0 format
We deliver in the exact structure that modern VLA models and LeRobot expect. No conversion scripts. No format wrangling. Point your training config at the dataset and run.
├── meta/
│ ├── info.json # Dataset metadata, features schema
│ ├── episodes.jsonl # Episode boundaries and lengths
│ ├── tasks.jsonl # Task descriptions and indices
│ └── stats.json # Pre-computed normalization statistics
│
├── data/
│ ├── chunk-000/
│ │ ├── episode_000000.parquet # State, action, timestamps per episode
│ │ ├── episode_000001.parquet
│ │ └── ...
│ └── chunk-001/
│ └── ...
│
├── videos/
│ ├── observation.images.base_0_rgb/
│ │ ├── episode_000000.mp4 # Third-person camera
│ │ ├── episode_000001.mp4
│ │ └── ...
│ ├── observation.images.left_wrist_0_rgb/
│ │ └── ... # Left wrist camera
│ └── observation.images.right_wrist_0_rgb/
│ └── ... # Right wrist camera (if bimanual)
│
└── assets/
└── motionledger_franka_v1/
└── norm_stats.json # Pre-computed normalization statsWhy this matters: The LeRobot v2.0 format is what modern VLA architectures consume natively. Custom formats require conversion code that introduces bugs and wastes engineering time. We've seen teams spend weeks debugging format mismatches.
Dataset metadata
The meta/info.json file defines the schema. LeRobot reads this to understand your observation and action spaces.
{
"codebase_version": "v2.0",
"robot_type": "franka",
"total_episodes": 812,
"total_frames": 487200,
"fps": 50,
"features": {
"observation.state": {
"dtype": "float32",
"shape": [8],
"names": [
"joint_0", "joint_1", "joint_2", "joint_3",
"joint_4", "joint_5", "joint_6", "gripper"
]
},
"action": {
"dtype": "float32",
"shape": [8],
"names": [
"joint_0", "joint_1", "joint_2", "joint_3",
"joint_4", "joint_5", "joint_6", "gripper"
]
},
"observation.images.base_0_rgb": {
"dtype": "video",
"shape": [480, 640, 3],
"video_info": {"fps": 30, "codec": "h264"}
},
"observation.images.left_wrist_0_rgb": {
"dtype": "video",
"shape": [480, 640, 3],
"video_info": {"fps": 30, "codec": "h264"}
}
},
"splits": {"train": "0:750", "val": "750:812"}
}Normalization statistics
Every VLA training run requires pre-computed normalization statistics. Without these, you'd run compute_norm_stats.py yourself—a process that takes hours on large datasets.
We include these in every delivery. Your team loads the dataset and starts training immediately.
{
"observation.state": {
"mean": [-0.0012, 0.2847, -0.0034, -1.8721, 0.0089, 2.1043, 0.7821, 0.42],
"std": [0.1823, 0.2156, 0.1934, 0.3127, 0.1567, 0.2891, 0.1423, 0.31],
"q01": [-0.4521, -0.1823, -0.4912, -2.5123, -0.3821, 1.4521, 0.2312, 0.0],
"q99": [0.4498, 0.7521, 0.4834, -1.2341, 0.4012, 2.7621, 1.3412, 1.0],
"min": [-0.5123, -0.2341, -0.5621, -2.6234, -0.4523, 1.3234, 0.1823, 0.0],
"max": [0.5234, 0.8123, 0.5512, -1.1234, 0.4823, 2.8512, 1.4123, 1.0]
},
"action": {
"mean": [0.0001, 0.0003, -0.0002, 0.0001, 0.0002, -0.0001, 0.0001, 0.48],
"std": [0.0234, 0.0312, 0.0289, 0.0198, 0.0267, 0.0234, 0.0178, 0.35],
"q01": [-0.0612, -0.0823, -0.0756, -0.0521, -0.0698, -0.0612, -0.0467, 0.0],
"q99": [0.0598, 0.0812, 0.0734, 0.0512, 0.0687, 0.0598, 0.0456, 1.0],
"min": [-0.0823, -0.1012, -0.0934, -0.0712, -0.0887, -0.0823, -0.0612, 0.0],
"max": [0.0812, 0.0998, 0.0912, 0.0698, 0.0876, 0.0812, 0.0598, 1.0]
}
}What each statistic is for
| Field | Used by | Purpose |
|---|---|---|
mean, std | Normalize transform | Z-score normalization: (x - mean) / std |
q01, q99 | NormalizeBounds transform | Robust scaling using 1st/99th percentiles (outlier-resistant) |
min, max | MinMax transform | Scale to [0, 1] or [-1, 1] range |
Action space conventions
VLA models expect a specific dimension ordering. Wrong ordering means your model predicts elbow angles when it should predict shoulder angles. We enforce the correct ordering in every delivery.
Single-arm (Franka, UR5, DROID)
dim[0]: joint_0 (shoulder pan) dim[1]: joint_1 (shoulder lift) dim[2]: joint_2 (elbow) dim[3]: joint_3 (wrist 1) dim[4]: joint_4 (wrist 2) dim[5]: joint_5 (wrist 3) dim[6]: joint_6 (flange) dim[7]: gripper [0=open, 1=closed]
Bimanual (ALOHA, Trossen)
dim[0:5]: left arm joints (6 DoF) dim[6]: left gripper [0=open, 1=closed] dim[7:12]: right arm joints (6 DoF) dim[13]: right gripper [0=open, 1=closed]
Delta vs. absolute actions
Most VLA models are trained on delta actions—the change from current state, not absolute positions. This is applied during training via the DeltaActions transform:
# Applied during training: action_delta = action_absolute - current_state # Gripper remains absolute (not delta): action_delta[gripper_idx] = action_absolute[gripper_idx]
We deliver absolute actions by default. The delta transform is applied at training time using the delta_indices mask in your training config.
Image key conventions
VLA models expect specific image key names. Using custom names like cam_top orwrist_camera requires writing transform code. We use the standard LeRobot names so your model loads the data without modification.
| Camera position | Standard key name | Feature path |
|---|---|---|
| Third-person / overhead | base_0_rgb | observation.images.base_0_rgb |
| Left wrist | left_wrist_0_rgb | observation.images.left_wrist_0_rgb |
| Right wrist | right_wrist_0_rgb | observation.images.right_wrist_0_rgb |
| Single wrist (non-bimanual) | wrist_0_rgb | observation.images.wrist_0_rgb |
| Additional base camera | base_1_rgb | observation.images.base_1_rgb |
Video format: H.264 encoded MP4, 30 FPS default (configurable to match your control frequency). Resolution preserved from source cameras. All frames are temporally aligned to the state/action timestamps.
Language instructions
High-quality datasets like DROID include multiple paraphrases per episode. This diversity is critical for language grounding—the model learns that "grab the cup" and "pick up the mug" mean the same action.
{"task_index": 0, "task": "Pick up the red block and place it in the bin"}
{"task_index": 1, "task": "Grab the crimson cube and put it in the container"}
{"task_index": 2, "task": "Lift the red object and drop it in the box"}
{"task_index": 3, "task": "Open the drawer"}
{"task_index": 4, "task": "Pull the drawer handle to open it"}
{"task_index": 5, "task": "Grasp the drawer and slide it out"}During training, the loader randomly samples one instruction per episode from available paraphrases. We collect 3+ paraphrases per unique task by default.
Timing synchronization
Anyone can claim "millisecond sync." We show you the actual alignment error over time. This is a simulated 60-second episode demonstrating our timing QA pipeline.
Note: This episode is simulated to demonstrate our timing QA and drift correction pipeline. Real client data available under NDA.
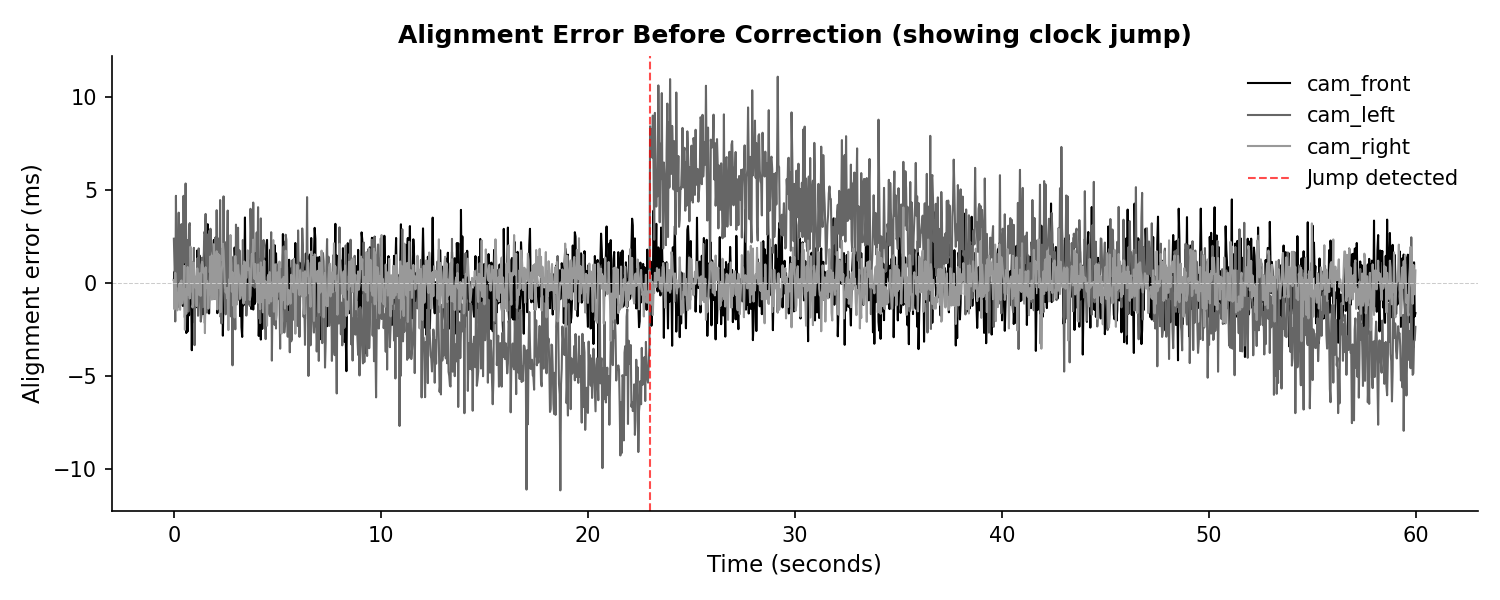
Alignment error before correction
Raw camera timestamps vs host clock. Notice the jump in cam_left at ~23s.
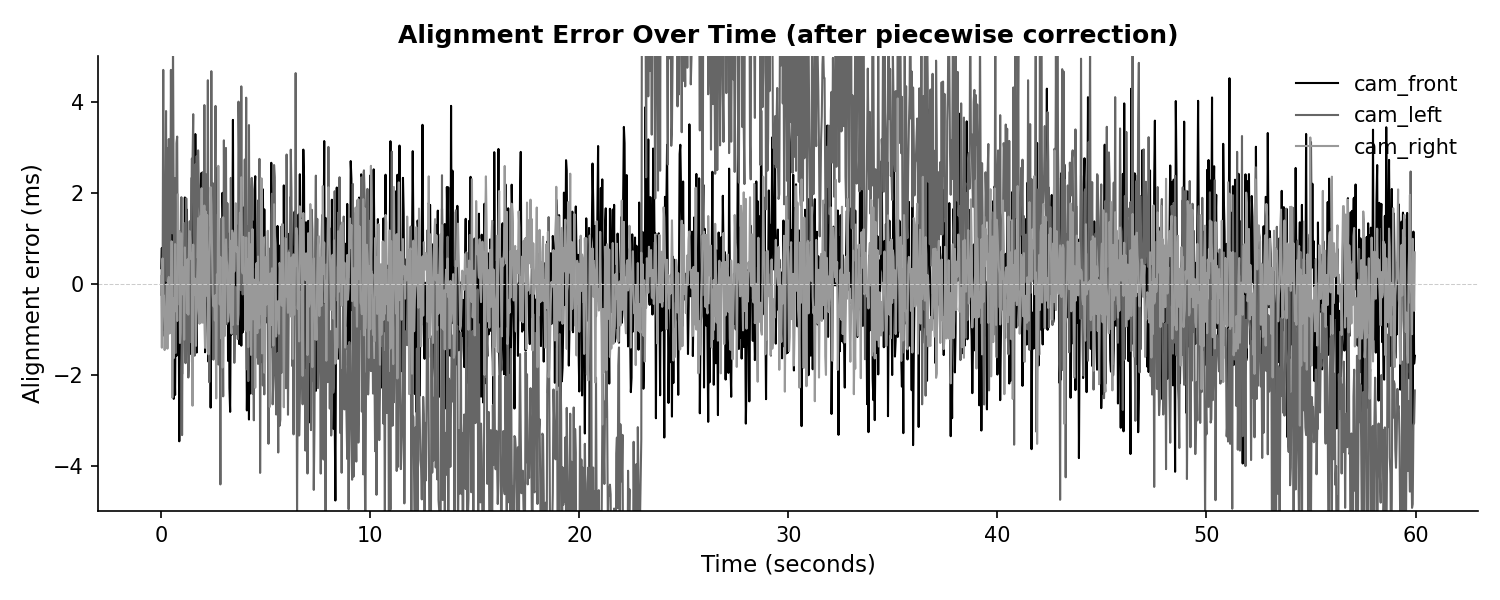
Alignment error after piecewise correction
After detecting jumps and refitting per segment, residual error is within ±5ms (p95), worst-case under 10ms.
Detected timing events
| Stream | Event | Time (s) | Magnitude | Action |
|---|---|---|---|---|
| cam_left | Clock jump | 23.0s | +12.0ms | Split + refit |
| cam_front | Normal drift | — | 15 ppm | Linear correction |
| cam_right | Normal drift | — | -10 ppm | Linear correction |
Download raw timestamp data
Inspect the actual nanosecond timestamps yourself.
QA report
Every drop includes a QA report. Full transparency about what was rejected and why.
| Metric | Value | Threshold | Status |
|---|---|---|---|
| Total episodes collected | 847 | — | — |
| Accepted | 812 | — | — |
| Rejected | 35 | — | — |
| Rejection rate | 4.1% | <10% | Pass |
| Avg frame drop rate | 0.3% | <1% | Pass |
| Max timestamp jitter (p95) | 4.8ms | <10ms | Pass |
| Max timestamp jitter (p99) | 8.2ms | <20ms | Pass |
Loading the dataset
Our datasets load directly into LeRobot. No custom loader required—use the standard API.
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset
# Point to your local dataset or HuggingFace repo
dataset = LeRobotDataset(
repo_id="motionledger/franka_pick_place_v1", # or local path
split="train",
)
# Access an episode
episode = dataset[0]
# Available keys
print(episode.keys())
# dict_keys([
# 'observation.state', # [T, 8] joint positions + gripper
# 'action', # [T, 8] joint commands + gripper
# 'observation.images.base_0_rgb', # [T, H, W, 3] third-person video
# 'observation.images.wrist_0_rgb', # [T, H, W, 3] wrist camera video
# 'timestamp', # [T] seconds from episode start
# 'task', # language instruction string
# 'episode_index', # int
# 'frame_index', # [T] int
# ])
# Normalization stats are loaded automatically
print(dataset.stats.keys())
# dict_keys(['observation.state', 'action'])Supported platforms
We've collected data and validated our pipeline on these platforms. Custom configurations supported—send us your URDF.
| Platform | Embodiment | Action dims | Status |
|---|---|---|---|
| Franka Emika Panda | Single-arm | 8 (7 joints + gripper) | Active |
| ALOHA (Trossen ViperX) | Bimanual | 14 (2×6 joints + 2 grippers) | Active |
| Universal Robots UR5e | Single-arm | 7 (6 joints + gripper) | Active |
| DROID (various) | Single-arm | 8 (7 DoF + gripper) | Active |
| Mobile ALOHA | Mobile bimanual | 16 (14 arm + 2 base) | Q1 2025 |
| Custom | Any | Configurable | Contact us |
Get a sample pack
Send us your spec and we'll build a sample pack in your exact format. Includes 10-20 episodes you can load and train on immediately.